Bella-RAG - 智能检索增强生成系统
Bella-RAG是一个基于Django和LlamaIndex框架的RAG(Retrieval-Augmented Generation)最佳实践,提供文档理解、索引构建、检索问答等完整的RAG基础能力。
🚀 核心特性
🏆 技术优势
- 🔥 业界领先的文档解析: 文档结构化解析效果业界领先,支持复杂版面和多模态内容理解,文档解析能力见bella-domify
- 🎯 高精度检索技术: 利用多路召回、small2big、rerank等技术,兼顾语义检索效果与信息完整度,多场景验证综合结果可用率 > 85%
- 🧠 Contextual RAG增强: 支持Contextual RAG技术,在chunk编码前预先添加解释性的上下文信息,��大幅提升检索准确率
- 🚀 Deep RAG智能agent模式: 基于Planning and Solve模式的智能agent,通过自动制定执行计划(圈定文件范围 → 阅读文件 → 反思)、步骤式执行和动态重规划,实现比传统RAG更优的问答效果
- 🔧 策略插件化架构: 检索策略完全可插拔,调用方可根据业务场景灵活调整检索策略及参数,满足不同领域需求
🛠️ 系统特性
- 多格式文档支持: 支持PDF、Word、Excel、HTML、Markdown等多种文档格式
- 向量化存储: 集成Qdrant向量数据库(可自部署)或腾讯向量数据库,提供高效的向量存储和检索
- 安全的混合架构: 向量数据库仅存储向量,原始文档内容安全存储在MySQL中
- 灵活的检索策略: 支持多种检索模式和重排序算法
- 完整的API: 提供完整的RESTful API接口
- 异步处理: 与file-api打通,支持Kafka异步任务处理
- 一键初始化: 提供自动化脚本快速完成环境配置
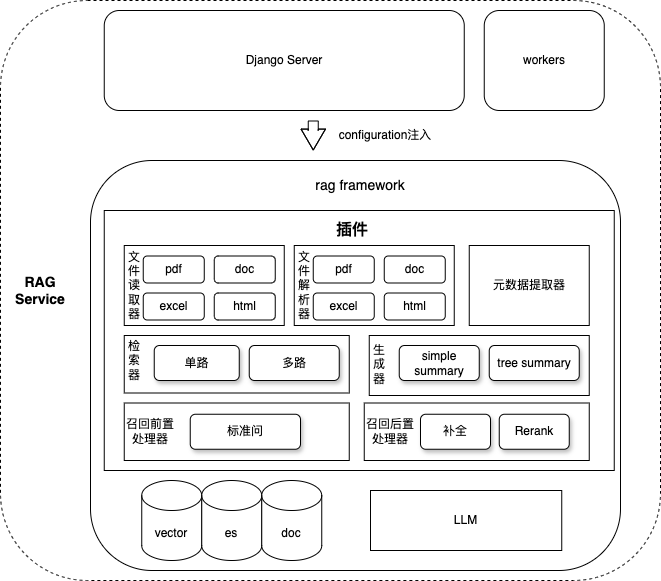
🏗️ 系统架构
整体架构图
处理流程图
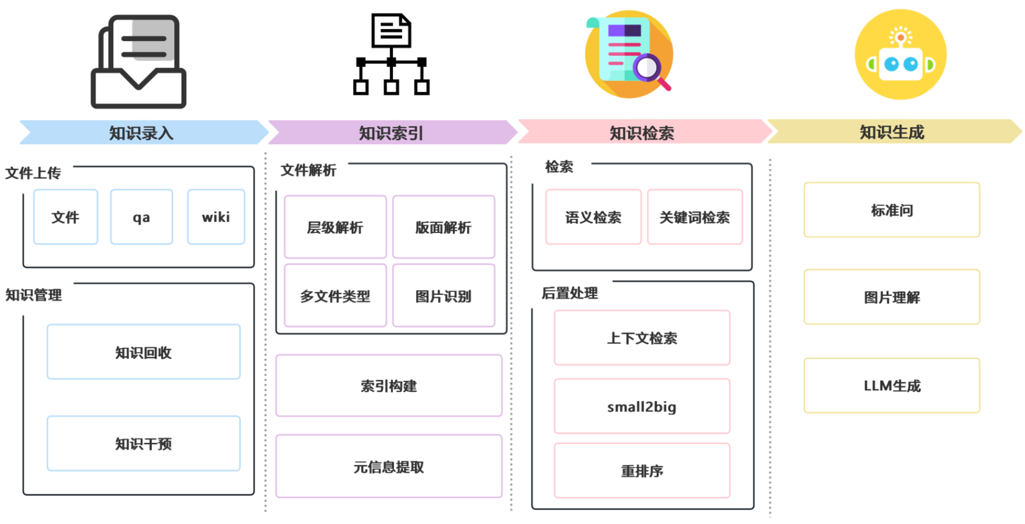 从文档上传到检索问答的完整处理流程
从文档上传到检索问答的完整处理流程
数据存储架构
Bella-RAG采用混合存储架构,将数据安全性和检索效率相结合:
向量数据库(Qdrant/腾讯云向量数据库):
- 存储文档和问答的向量化表示
- 不存储原始文本内容(安全考虑)
- 支持高效的相似度检索
- 包含三个集合:主文档向量、QA向量、文档总结向量
- 支持使用Qdrant自部署,或者企业版的腾讯云向量数据库
关系型数据库(MySQL):
- 存储文档的原始内容和元数据
- 提供结构化数据查询能力
- 确保数据的持久性和一致性
搜索引擎(Elasticsearch):
- 提供关键词检索能力
- 补充向量检索的不足
- 支持复杂的文本查询和过滤
📋 环境要求
- Docker >= 20.0
- Docker Compose >= 2.0
- 可用内存 >= 4GB
- OpenAI API密钥(或兼容的API服务)
💡 提示: 所有服务通过 Docker Compose 一键部署,无需手动安装 MySQL、Redis、Qdrant 等组件
🎯 向量数据库选择
Bella-RAG 支持多种向量数据库,您可以根据需求选择:
🔥 Qdrant
- ✅ 完全开源免费:MIT许可证,无使用限制
- ✅ 本地部署:数据完全可控,无需依赖第三方服务
- ✅ 一键启动:Docker Compose 自动部署和初始化
- ✅ 易扩展:支持水平扩展和分布式部署
🏢 腾讯云向量数据库=
- ✅ 托管服务:无需运维,自动备份和高可用
- ✅ 企业级:支持大规模数据和高并发访问
- ✅ 完整生态:与腾讯云其他服务深度集成
- ⚙️ 需要配置:需要腾讯云账号和API密钥
📚 相关文档
- 快速开始 - 如何快速部署和使用Bella-RAG
- Deep RAG介绍 - 了解Deep RAG智能agent模式
- API接口文档 - 完整的API接口规范和协议
- 高级配置 - 高级特性和配置说明
📄 许可证
本项目采用 MIT许可证。
项目地址: GitHub